My latest infographic, Skilling Up for Data Curation, using Piktochart examines the skills and tools I’ll need for data curation at my campus. The infographic was used for a poster session on the topic for the Fall 2013 conference of the Western New York/Ontario Chapter of the Association of College Research Libraries (ACRL).
There has been a lot of discussion over the last several year about the role that libraries should play in data curation efforts at their institutions. Technical advances have made it possible for the creation of larger and larger amounts of information/data/research/scholarship. How best to manage and preserve this influx is under debate, especially given the challenges; the sheer volume, different media types, intellectual property issues, obsolescence of formats/software and lack of metadata to name a few…
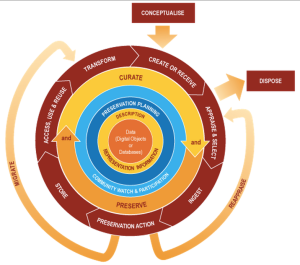
DCC Curation Lifecycle Model
What we do know is that data curation must be a collaborative effort between librarians and data creators for two important reasons: to have the metadata necessary for curation later in the data lifecycle and to education data creators about the need for standardization of metadata. Consistent standards used by researchers within a discipline, or better yet across disciplines, will allow for the opportunity to automate some (perhaps all) of the curation process and the possibility for adding smaller datasets to the corpus of curated data outside our own small institution for reuse by others, attaining an even greater return on investment.
Digital curation is far removed from the the institutional repository of the past. Reappraisal and providing access in ways (and formats) that the data can be readily reused is key so that our digital collection don’t wind up looking like an old attic where we’ve abandoned our institutional data.
Through a series of discussions with faculty on our campus this summer, we found that, as yet, there is no great demand for data curation with respect to faculty research. However, we have begun developing skill sets in this area so we’ll be prepared with technology and infrastructure options in anticipation of future needs.
During these discussions, we found several areas where the library immediately could serve:
- Provide assistance locating discipline specific repositories for finding and publishing research data.
- Provide instruction or workshops for undergraduate students to improve skills in managing both laboratory and their own data.
- Provide assistance in developing data management plans on funding applications.
- Identify faculty work or research projects that could/should be digitally curated.
Education and ongoing discussion with faculty about developing standards for metadata and opportunities and benefits for open data sharing will be key. We also have the opportunity to to be selective about the projects we pursue and to pace our digital initiatives in ways that are practicable in terms of resources, time and funding.
References:
Bird, C., Willoughby, C., Coles, S., and Frey, J. (2013). Data curation: Issues in the chemical sciences. Information Standards Quarterly, 25(3): 7-12.
Digital Curation Centre. (n.d.). Data curation lifecycle model.
DataCite: Helping you find access, and reuse data. (n.d.). Why cite data?
Lee, C. A., Tibbo, H., & Schaefer, J. C. (2007a). DigCCurr: Building an international digital curation curriculum & the Carolina Digital Curation Fellowship Program.
Schirrwagen, Jochen, Paolo Manghi, Natalia Manola, Lukasz Bolikowski, Najla Rettberg, Birgit Schmidt. (2013). Data Curation in the OpenAIRE scholarly communication infrastructure. Information Standards Quarterly, 25(3): 13-19.
Smith, K. (2009). All universities should have an institutional repository. Bulletin of the American Society for Information Science and Technology (Online), 35(4), 11-31.
 Introduced in 2005, Google Earth is a three-dimensional virtual globe overlaid with dynamic data layers that let you explore land, oceans, moon and stars. There’s even a tour guide option that will give you historical information about significant places and events.
Introduced in 2005, Google Earth is a three-dimensional virtual globe overlaid with dynamic data layers that let you explore land, oceans, moon and stars. There’s even a tour guide option that will give you historical information about significant places and events. Governments and businesses are using it to make decision for location based projects by analyzing geospatial information layered by topographic, demographic, traffic data, and the like. For example, the New York State Department of Transportation has developed a Traffic Data Viewer that uses data from the National Geodetic Survey (NGS) Database (a google earth application) to display published traffic data graphically. County administrators can use this resource to plan repaving efforts or an entrepreneur could use local traffic patterns to determine the best location to open up their new start-up.
Governments and businesses are using it to make decision for location based projects by analyzing geospatial information layered by topographic, demographic, traffic data, and the like. For example, the New York State Department of Transportation has developed a Traffic Data Viewer that uses data from the National Geodetic Survey (NGS) Database (a google earth application) to display published traffic data graphically. County administrators can use this resource to plan repaving efforts or an entrepreneur could use local traffic patterns to determine the best location to open up their new start-up. Educators are using it extensively in many different disciplines and ways, such as understanding global development, selecting and visualizing field study sites, studying land-use law and to depict the locations of many of the disputes, visualizing historical events and issues like the Trans-Atlantic slave trade routes, the underground railroad, the abolishment of slavery in Great Britain, mapping field trip routes, analyzing communication systems and so much more.
Educators are using it extensively in many different disciplines and ways, such as understanding global development, selecting and visualizing field study sites, studying land-use law and to depict the locations of many of the disputes, visualizing historical events and issues like the Trans-Atlantic slave trade routes, the underground railroad, the abolishment of slavery in Great Britain, mapping field trip routes, analyzing communication systems and so much more.






